

What You Should Know:
– Kahun, a company specializing in evidence-based clinical AI, has released a new study comparing the medical capabilities of popular large language models (LLMs) to human experts.
– The findings reveal the limitations of current LLMs in providing reliable information for clinical decision-making.
The Study: Comparing LLMs to Medical Professionals
- LLMs Tested: OpenAI’s GPT-4 and Anthropic’s Claude3-Opus
- Evaluation Method:
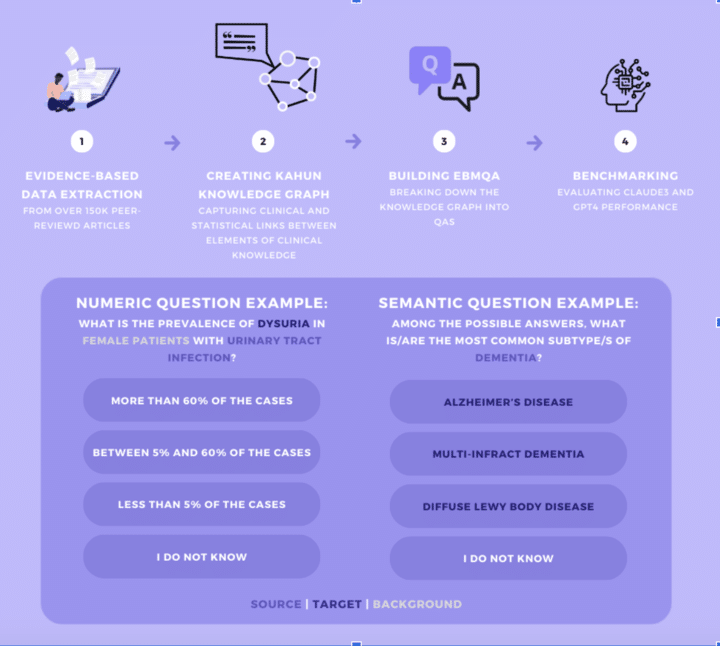
- 105,000 evidence-based medical questions and answers (Q&As) were developed by Kahun based on real-world physician queries.
- Q&As covered various medical disciplines and were categorized into numerical (e.g., disease prevalence) and semantic (e.g., differentiating dementia subtypes).
- Six medical professionals answered a subset of Q&As for comparison.
- Key Findings:
- Both LLMs performed better on semantic questions (around 68% accuracy) than numerical questions (around 64% accuracy). Claude3 showed slight superiority in numerical accuracy.
- LLM outputs varied significantly for the same prompt, raising concerns about reliability.
- Medical professionals achieved significantly higher accuracy (82.3%) compared to LLMs (Claude3: 64.3%, GPT-4: 55.8%) on identical questions.
- LLMs exhibited questionable ability to admit uncertainty (“I don’t know”) despite offering this option.
Concerns and Implications for Clinical Use
The study highlights the limitations of current LLMs in a clinical setting due to:
- Inaccurate medical information: Both LLMs provided incorrect answers for a significant portion of the questions, raising concerns about patient safety.
- Lack of domain-specific knowledge: LLMs are trained on massive datasets that may not include high-quality medical sources.
- Unreliable output: Variability in responses for the same prompt undermines the trustworthiness of LLM outputs.
Physician Concerns Confirmed
This study aligns with physician concerns about using generative AI models in clinical practice. Physicians emphasize the need for models trained on reliable medical sources and the importance of understanding the limitations of current technology.
While LLMs show promise, further development is needed to ensure their accuracy and reliability in clinical settings. In the meantime, solutions like Kahun’s offer a more secure and trustworthy path for AI integration into healthcare.
“While it was interesting to note that Claude3 was superior to GPT-4, our research showcases that general-use LLMs still don’t measure up to medical professionals in interpreting and analyzing medical questions that a physician encounters daily. However, these results don’t mean that LLMs can’t be used for clinical questions. In order for generative AI to be able to live up to its potential in performing such tasks, these models must incorporate verified and domain-specific sources in their data,” says Michal Tzuchman Katz, MD, CEO and Co-Founder of Kahun. “We’re excited to continue contributing to the advancement of AI in healthcare with our research and through offering a solution that provides the transparency and evidence essential to support physicians in making medical decisions.
The full preprint draft of the study can be found here: https://arxiv.org/abs/2406.03855